آیا تا به حال برایتان پیش آمده که یک مدل یادگیری ماشین بسازید که در دادههای آزمایشی شما عملکرد درخشانی داشته باشد اما در مواجهه با سناریوهای دنیای واقعی دچار مشکل شود؟ 🤔 این دام رایج اغلب ناشی از اتکا به یک تقسیمبندی تکی آموزش/آزمون است که ممکن است نتواند تنوع کامل دادههایی را که مدل شما با آن روبرو خواهد شد، نشان دهد. اینجاست که یک تکنیک قدرتمندتر به نام اعتبارسنجی متقابل (Cross-Validation) به کمک میآید.
این راهنما قصد دارد به زبانی ساده اعتبارسنجی متقابل را رمزگشایی کند، برتری آن را نسبت به روش استاندارد نگهدار (hold-out) نشان دهد و به شما آموزش دهد که چگونه آن را با کدهای ساده پیادهسازی کنید.

اعتبارسنجی متقابل دقیقاً چیست؟
اعتبارسنجی متقابل یک تکنیک ارزیابی است که برای سنجش تعمیمپذیری نتایج یک تحلیل آماری به یک مجموعه داده مستقل استفاده میشود. به جای یک تقسیمبندی واحد، این روش دادهها را به چندین زیرمجموعه تقسیم میکند. سپس مدل روی برخی از این زیرمجموعهها آموزش دیده و روی زیرمجموعه باقیمانده آزمایش میشود. این فرآیند چندین بار تکرار میشود و در هر بار، یک زیرمجموعه متفاوت نقش مجموعه آزمون را ایفا میکند. در نهایت، معیارهای عملکرد از هر اجرا میانگینگیری میشوند تا تخمین پایدارتر و قابل اعتمادتری از عملکرد مدل ارائه دهند.
این روش را مانند برگزاری چندین آزمون کوچک از مدل خود به جای یک آزمون نهایی بزرگ در نظر بگیرید. این رویکرد تضمین میکند که امتیاز عملکرد صرفاً یک اتفاق شانسی بر اساس یک تقسیمبندی خوششانس یا بدشانس دادهها نیست.

مزیت کلیدی این روش، قابلیت اطمینان آن است. این کار تصادفی بودن ناشی از یک مجموعه آزمون تکی را کاهش میدهد و تخمین عملکرد شما را دقیقتر میکند. همچنین از دادههای شما بهینهتر استفاده میکند، که به ویژه هنگام کار با مجموعه دادههای کوچک بسیار حیاتی است، زیرا هر نقطه داده در تکرارهای مختلف هم برای آموزش و هم برای اعتبارسنجی استفاده میشود.
انواع رایج اعتبارسنجی متقابل
انواع مختلفی از اعتبارسنجی متقابل وجود دارد که هر کدام برای سناریوهای متفاوتی مناسب هستند:
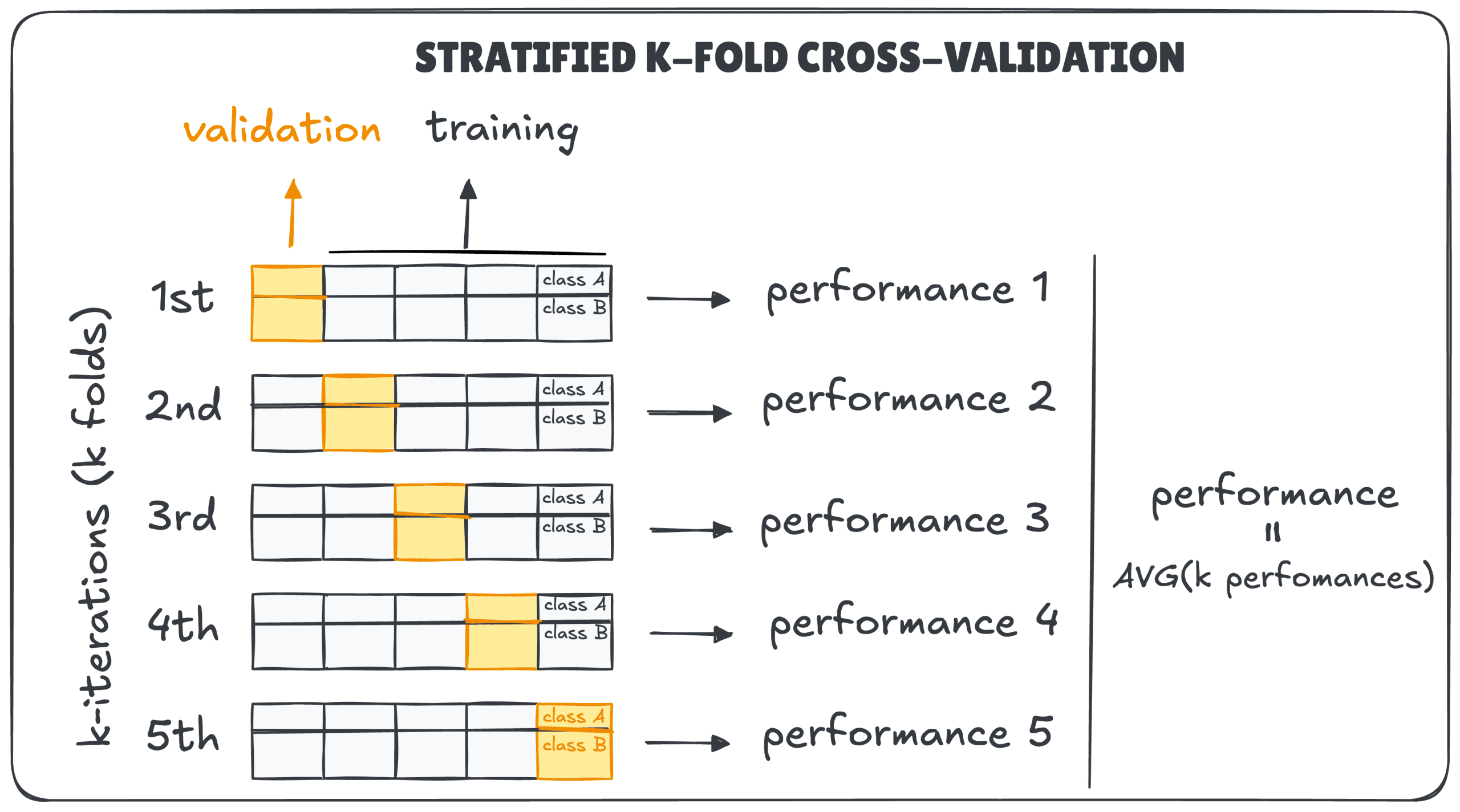
- اعتبارسنجی متقابل K-Fold: این رایجترین روش است. مجموعه داده به ‘k’ بخش مساوی یا ‘فولد’ تقسیم میشود. مدل روی k-1 فولد آموزش دیده و روی فولدی که کنار گذاشته شده است، آزمایش میشود. این فرآیند تا زمانی که هر فولد یک بار به عنوان مجموعه آزمون عمل کند، تکرار میشود. امتیاز نهایی میانگین تمام k اجرا است.
- K-Fold طبقهبندیشده (Stratified): هنگام کار با مسائل طبقهبندی نامتعادل، این روش ضروری است. این روش تضمین میکند که هر فولد نسبت یکسانی از برچسبهای کلاس را مانند مجموعه داده اصلی داشته باشد. این کار از وضعیتی جلوگیری میکند که یک فولد آزمون ممکن است تعداد کمی یا هیچ نمونهای از یک کلاس اقلیت داشته باشد و به ارزیابی منصفانهتری منجر میشود.
- اعتبارسنجی متقابل ترک یک نمونه (LOOCV): این یک نسخه افراطی از K-Fold است که در آن ‘k’ برابر با تعداد نقاط داده است. مدل روی تمام نقاط داده به جز یکی آموزش داده میشود و آن یک نمونه برای آزمایش استفاده میشود. اگرچه این روش تخمین عملکرد تقریباً بدون بایاس ارائه میدهد، اما از نظر محاسباتی بسیار گران است.
- اعتبارسنجی متقابل سری زمانی: برای دادههایی با ترتیب زمانی (مانند قیمت سهام)، برهم زدن تصادفی دادهها یک اشتباه بزرگ است زیرا میتواند منجر به نشت داده (استفاده از آینده برای پیشبینی گذشته) شود. این روش از یک پنجره ‘غلتان’ یا ‘در حال گسترش’ برای ایجاد فولدهایی استفاده میکند که ترتیب زمانی دادهها را رعایت میکنند.




تعادل بین بایاس و واریانس
اعتبارسنجی متقابل ابزاری قدرتمند برای مدیریت موازنه بایاس-واریانس است. یک تقسیمبندی تکی آموزش/آزمون میتواند واریانس بالایی داشته باشد زیرا نتیجه به شدت به این بستگی دارد که کدام نقاط داده خاص در مجموعه آزمون قرار گرفتهاند. با میانگینگیری عملکرد در چندین مجموعه آزمون، اعتبارسنجی متقابل این واریانس را به طور قابل توجهی کاهش میدهد و به شما یک تخمین عملکرد پایدارتر و قابل اعتمادتر میدهد.
مثال عملی در پایتون
در اینجا نحوه پیادهسازی اعتبارسنجی متقابل ۵-فولد با استفاده از Scikit-learn بر روی مجموعه داده Iris آمده است:
from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
model = LogisticRegression(max_iter=1000)
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kfold)
print("Cross-validation scores:", scores)
print("Average accuracy:", scores.mean())نکات پایانی
گنجاندن اعتبارسنجی متقابل در گردش کار یادگیری ماشین شما یک گام حیاتی به سوی ساخت مدلهایی است که میتوانید به آنها اعتماد کنید. این روش فراتر از یک امتیاز آزمون تکی و بالقوه گمراهکننده میرود تا به شما درک جامعی از نحوه عملکرد احتمالی مدل شما بر روی دادههای دیدهنشده بدهد. به یاد داشته باشید که دادههای خود را برهم بزنید (مگر اینکه سری زمانی باشد)، از فولدهای طبقهبندیشده برای طبقهبندی استفاده کنید و مراقب نشت داده باشید. با انجام این کار، مدلهای قابل اعتمادتر و قویتری خواهید ساخت.
منبع: KDnuggets