دنیای رونویسی گفتار مبتنی بر هوش مصنوعی در حال داغتر شدن است و تیم Qwen علیبابا با معرفی مدل جدید خود، Qwen3-ASR-Flash، چالشی جدی برای رقبا ایجاد کرده است. 🚀 این تنها یک بهروزرسانی تدریجی دیگر نیست؛ بلکه یک جهش بزرگ به جلو است که بر پایه هوش قدرتمند Qwen3-Omni ساخته شده و بر روی یک مجموعه داده عظیم با دهها میلیون ساعت داده گفتاری آموزش دیده است.
تیم سازنده میگوید این مدل برای ارائه دقت فوقالعاده بالا، حتی در محیطهای صوتی چالشبرانگیز یا الگوهای زبانی پیچیده، مهندسی شده است. اما عملکرد آن در برابر غولهای این صنعت واقعاً چگونه است؟
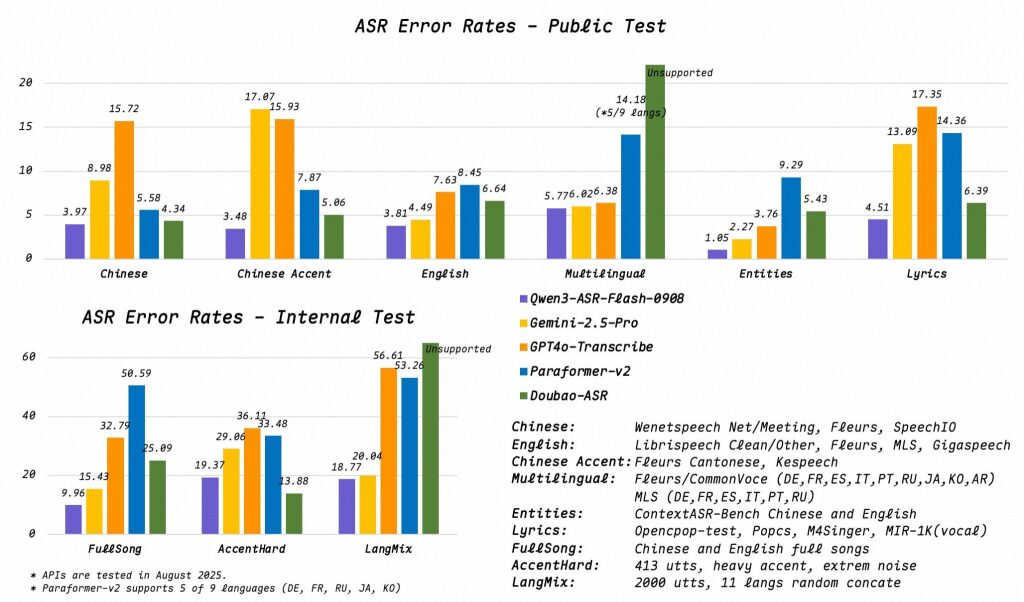
معیارهای عملکردی آن بسیار چشمگیر هستند. در یک آزمون عمومی برای زبان چینی استاندارد، Qwen3-ASR-Flash به نرخ خطای کاراکتر تنها ۳.۹۷٪ دست یافت. برای درک بهتر این موضوع، رقبایی مانند Gemini-2.5-Pro و GPT4o-Transcribe با نرخهای خطای ۸.۹۸٪ و ۱۵.۷۲٪ به ترتیب، بسیار عقبتر قرار گرفتند. این مدل همچنین در تشخیص لهجههای مختلف چینی با نرخ خطای ۳.۴۸٪ عملکردی عالی داشت.
تواناییهای آن به زبان چینی محدود نمیشود. در زبان انگلیسی، این مدل به نرخ خطای بسیار رقابتی ۳.۸۱٪ رسید و به راحتی از Gemini با ۷.۶۳٪ و GPT4o با ۸.۴۵٪ پیشی گرفت.
اما شگفتانگیزترین نمایش قدرت آن در حوزهای است که مدتها برای هوش مصنوعی یک کابوس بوده است: رونویسی موسیقی. 🎶 هنگامی که وظیفه تشخیص اشعار از روی آهنگها به آن محول شد، Qwen3-ASR-Flash نرخ خطای تنها ۴.۵۱٪ را ثبت کرد که پیشرفت عظیمی نسبت به رقبایش محسوب میشود. آزمایشهای داخلی روی آهنگهای کامل نیز این برتری را تأیید کرد؛ جایی که نرخ خطای ۹.۹۶٪ را در مقایسه با ۳۲.۷۹٪ برای Gemini-2.5-Pro و نرخ خیرهکننده ۵۸.۵۹٪ برای GPT4o-Transcribe به دست آورد.

فراتر از دقت خام، این مدل ویژگیهای نوآورانهای را معرفی میکند. یکی از مهمترین آنها جهتدهی متنی انعطافپذیر (flexible contextual biasing) است. فرآیند خستهکننده قالببندی لیست کلمات کلیدی را فراموش کنید. این سیستم به کاربران اجازه میدهد تا متن پسزمینه را تقریباً در هر فرمتی—یک لیست ساده، یک سند کامل، یا حتی ترکیبی نامنظم—به مدل بدهند تا رونویسیهای سفارشی و آگاه از زمینه دریافت کنند. این ویژگی نیاز به پیشپردازش پیچیده داده را از بین میبرد و به طور هوشمندانه دقت را افزایش میدهد بدون اینکه اطلاعات نامرتبط باعث اختلال در عملکرد آن شود.
جاهطلبی علیبابا به وضوح جهانی است. این مدل رونویسی دقیقی را برای ۱۱ زبان از یک سیستم واحد ارائه میدهد که شامل گویشها و لهجههای متعددی است. این مدل از زبان چینی (ماندارین، کانتونی، سیچوآنی، مینان و وو) پشتیبانی عمیقی دارد و لهجههای مختلف انگلیسی (بریتانیایی، آمریکایی و غیره) را مدیریت میکند. فهرست زبانهای پشتیبانیشده همچنین شامل فرانسوی، آلمانی، اسپانیایی، ایتالیایی، پرتغالی، روسی، ژاپنی، کرهای و عربی است.
در نهایت، این مدل میتواند به طور خودکار زبانی که صحبت میشود را شناسایی کند و در فیلتر کردن صداهای غیرگفتاری مانند سکوت یا نویز پسزمینه مهارت دارد و خروجی بسیار تمیزتری را تضمین میکند. این قابلیتها واقعاً میتوانند نسل بعدی ابزارهای رونویسی هوش مصنوعی را متحول کنند.
منبع: AI News