
آیا تا به حال متوجه شدهاید که حتی پیشرفتهترین مدلهای هوش مصنوعی نیز گاهی اوقات تصاویری را که به آنها میدهید نادیده میگیرند و بیشتر به متن تکیه میکنند؟ این فقط تصور شما نیست. یک مطالعه پیشگامانه نشان میدهد که این مسئله یک ویژگی عجیب یا نتیجه دادههای آموزشی جانبدارانه نیست، بلکه یک نقص اساسی است که در معماری این سیستمها تنیده شده است.
پژوهشگرانی به نامهای شینهان ژنگ، هویو وو و شوتینگ وانگ از دانشگاه علم و فناوری چین، به همراه هاییون جیانگ از دانشگاه جیائو تونگ شانگهای، به اعماق عملکرد درونی مدلهای زبان بزرگ چندوجهی (MLLMs) مانند LLaVA و Qwen پرداختهاند. برای مدتها، نظریه غالب این بود که اگر یک هوش مصنوعی متن را ترجیح میدهد، حتماً با دادههای متنی بیشتری نسبت به دادههای بصری آموزش دیده است. این تحقیق جدید، این تصور را به کلی به چالش میکشد.
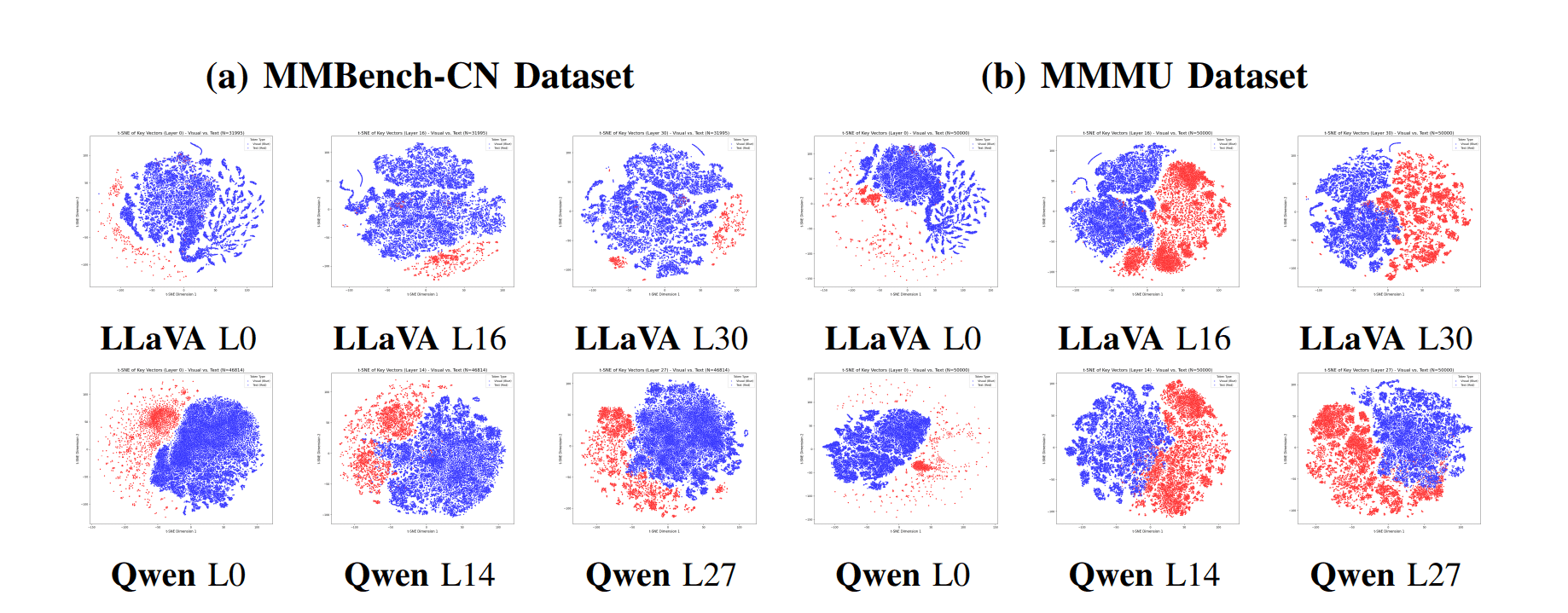
این تیم کشف کرد که ریشه مشکل در «مکانیسم توجه» (attention mechanism) مدل نهفته است؛ مؤلفهای که مسئول سنجش اهمیت اطلاعات مختلف است. روشی که این مدلها دادههای بصری را پردازش و بازنمایی میکنند، اساساً با نحوه مدیریت متن متفاوت است. این امر چیزی را ایجاد میکند که محققان آن را «جدایی فضای کلید» (key space separation) مینامند.
تصور کنید مغز مدل دو اتاق جداگانه دارد: یکی برای درک متن و دیگری برای درک تصاویر. بخشی از مغز که تصمیمگیری میکند، عمدتاً در اتاق متن آموزش دیده است. هنگامی که از آن خواسته میشود اطلاعات هر دو اتاق را در نظر بگیرد، به طور طبیعی به سمت زبان آشنای اتاق متن کشیده میشود و عملاً بینشهای ارزشمند اتاق تصویر را به حاشیه میراند.
دانشمندان با استفاده از تحلیلهای پیچیده و تکنیکهای کاهش ابعاد، توانستند این جدایی را به تصویر بکشند. آنها دریافتند که بازنماییهای داخلی (یا «بردارهای کلید») برای توکنهای تصویر، در فضایی متمایز و دور از گسترهای که توسط توکنهای متن اشغال شده، خوشهبندی شدهاند. این فقط یک تفاوت جزئی نیست؛ بلکه یک شکاف آماری قابل توجه و قابل اندازهگیری است که حتی در معماریهای پیشرفتهتر MLLM نیز باقی میماند. رمزگشای مدل که به طور گسترده بر روی زبان پیشآموزش دیده است، ذاتاً با کلیدهای متنی راحتتر است و اولویت بالاتری به آنها میدهد که منجر به عدم استفاده کافی از شواهد بصری میشود.
این کشف یک گام حیاتی به جلو است. این به ما میگوید که صرفاً ارائه مجموعه دادههای متعادلتر به مدل، مشکل را حل نخواهد کرد. برای ساختن هوش مصنوعی واقعاً هوشمند و قابل اعتمادی که بتواند به طور مؤثر با تصاویر و کلمات استدلال کند، باید به نقطه شروع بازگردیم و این محدودیتهای معماری بنیادی را برطرف کنیم. تمرکز باید از مدیریت داده به سمت طراحی مجدد مکانیسمهای اصلی تغییر کند که به این مدلها اجازه میدهد دنیا را به شیوهای یکپارچهتر ببینند و بخوانند.
منبع: Quantum Zeitgeist